
At Jest, we’ve found that playable ads are a highly effective means of introducing users to messaging apps. We call these interactive introductions onboardings.
Like traditional mobile user acquisition (UA) creatives, onboardings are a volume game: the more concepts we can test, the more chances we have to find winners. But producing a playable onboarding is much heavier than producing a static ad or video. It is closer to building a small interactive experience: designed, implemented, tested, reviewed, and shipped.
Manual development simply does not scale to the volume we want.
Every onboarding starts the same way: a folder full of design files, screenshots, exported assets, audio, and notes describing how the experience should feel.
That sounds simple until you try to turn it into something interactive.
Someone has to interpret the design. Someone has to figure out which layers belong to which stage. Someone has to translate animation notes into actual behavior. Someone has to wire the registration flow, build the project, test the core loop, compare it against the mockups, and push a working build back for review.
The work is highly repetitive, but it is not rigid. A single missing detail in a spec can become a broken interaction in the build. A single wrong assumption about a layer, a stage transition, or a registration asset can send the whole onboarding off course.
We did not need a generic coding assistant. We needed a production system.
Just as importantly, we needed every run through that system to leave behind structured evidence we could learn from.
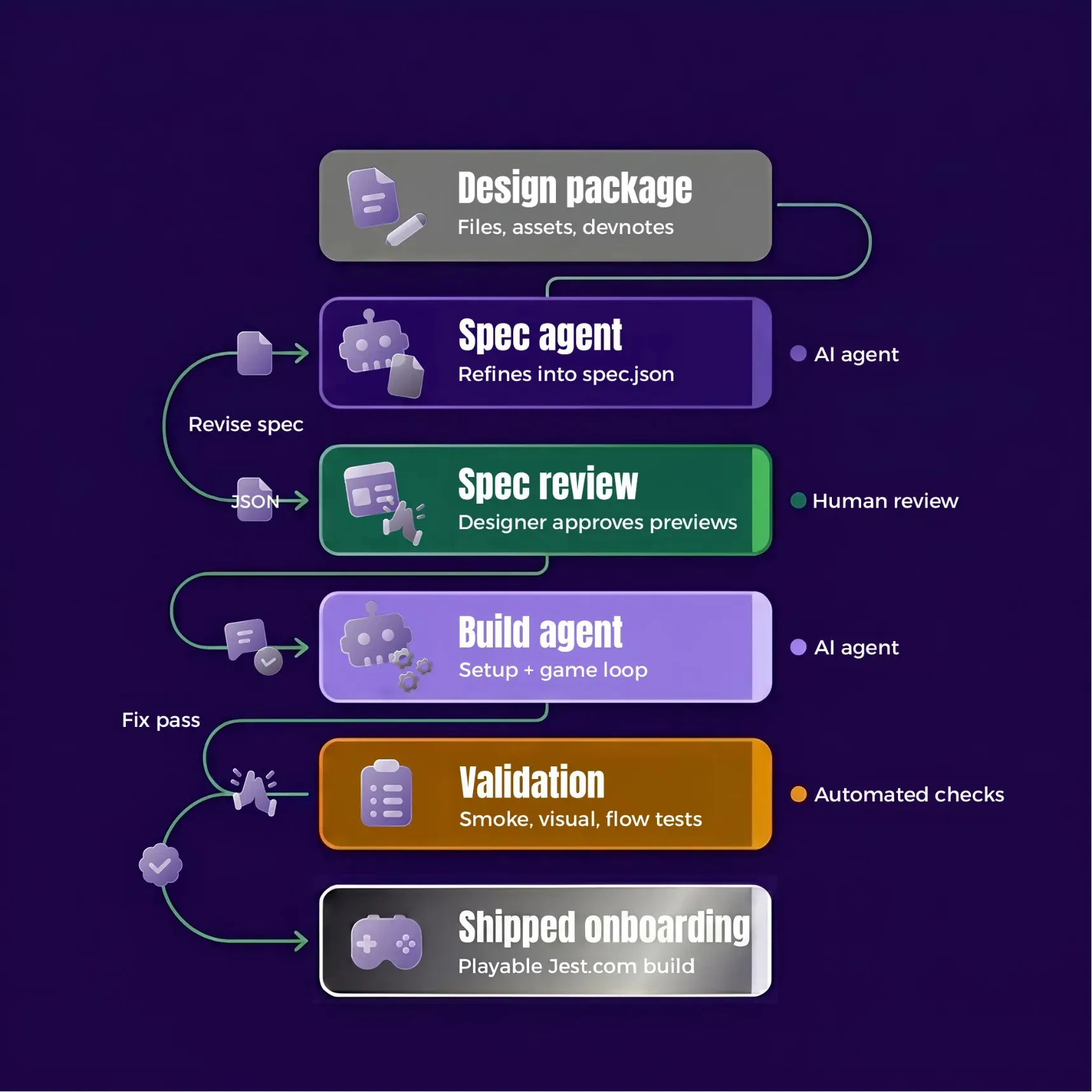
So we built The Factory: a multi-stage pipeline that turns onboarding inputs into a production-grade playable ad on Jest, with AI agents embedded inside deterministic scripts, validation layers, and human review loops.
Why one agent was not enough
At first glance, this looks like something you could hand to one capable model: read the design, build the onboarding, and ship it.
In practice, that breaks down quickly.
Reading a design file and writing a structured specification is a very different job from implementing interactive code. Validating visual fidelity is a different job again. Reviewing designer feedback and making a narrow fix pass is different from both.
When one agent tries to do all of it in one long trajectory, two things happen. First, too much irrelevant context accumulates. Second, the same reasoning that produced the implementation starts biasing the review of that implementation.
We wanted narrower roles with clearer incentives.
So instead of building one giant agent, we split the work into a factory:
- A Spec Agent that turns design intent into a canonical onboarding spec.
- A Build Agent pipeline that turns that spec into a playable build.
- Scripted validation and deployment stages around both.
- Review loops that let humans correct the right thing at the right layer.
The result is not “AI builds onboardings.” It is a system where each stage owns a specific problem, hands off a concrete artifact, and gets checked before the next stage begins.
It is also a system where every stage produces usable data: what the model assumed, what the validator caught, what the reviewer changed, and what finally shipped.
How The Factory works
The Factory starts when an onboarding moves through a status change in our internal workflow. That status acts as the control plane. From there, jobs are queued, workspaces are created, and the pipeline begins.
Stage 1: turning design inputs into a spec
The first half of the system is the Spec Agent.
It ingests the onboarding package, reads the page for metadata, downloads the design and support files, converts docs where needed, and extracts a structured manifest from the design. That manifest includes the layers, positions, sequences, stack groups, registration assets, and other raw material the rest of the system needs.
Before any AI refinement happens, we run deterministic checks on the inputs. Is the design in the correct format? Are there screenshots? Are the devnotes substantial enough to describe the flow? Are the sequence groups valid? If the inputs are incomplete, the system stops early and asks for better material instead of hallucinating its way forward.
From there, we generate a draft spec automatically. This draft already knows a lot: stage structure, asset positions, z-order, audio files, registration textures, and the first pass at grouping the design into onboarding stages. Then the Spec Agent takes over.
Its job is not to invent the onboarding. Its job is to refine the draft into a spec that a builder can implement without guessing. It writes the design concept, behavior descriptions, interaction types, motion assertions, and review notes. It also grounds key animation and timing decisions by searching against shipped onboarding patterns rather than making them up from scratch.
The output of this stage is a single source of truth: spec.json.
That file is the contract for everything downstream.
We also generate visual previews from the spec and publish an AI review page for the designer. That matters because feedback at the spec layer is much cheaper than feedback after code has already been written. It also means the factory starts accumulating useful signals early: what assumptions were surfaced, what references were used, and where the first ambiguities showed up.
Stage 2: turning the spec into a playable onboarding
Once the spec is approved, the Build Agent takes over.
This stage begins with a deterministic project initializer. It clones our template, copies in the assets, generates asset packs, wires audio, verifies that referenced files exist, and creates a clean project workspace. In other words, it removes the boring failure modes before an LLM ever touches the code.
Inside the build stage, the work is split again.
The Setup Agent creates the visual foundation. It declares sprites, sets positions, builds containers, wires stage one entry behavior, creates the scaffold used by our validators, and sets up the state and logging hooks the rest of the pipeline expects.
The Core-Loop Agent extends that foundation into a real interactive experience. It implements interactions, round logic, state transitions, wrong-answer behavior, celebrations, loop-back conditions, and end states. It is focused on behavior, not on project bootstrapping or deployment.
That split is deliberate. The static layer and the behavior layer fail in different ways. Treating them as separate jobs makes both more reliable.
Stage 3: validating what was built
After the onboarding is built, The Factory does not assume success.
We run smoke tests to catch runtime crashes that compilation misses. We spin up a dev server and compare live stage screenshots against the generated previews. We simulate the onboarding flow through the browser to verify that taps, waits, and transitions actually work end to end.
If validation surfaces blocker issues, the pipeline dispatches a targeted fix pass and re-checks the result.
After that, we run advisory passes for effects and critique, then wire the registration flow, build the production bundle, and upload the final onboarding.
Every phase writes back to a canonical build document. That gives us checkpoints, provenance, deployments, review history, and enough state to resume safely if a run is interrupted.
It also gives us a record of how onboardings move through the factory: where specs break down, where builds fail, what validators catch, what reviewers correct, and which patterns ultimately ship cleanly.
The review loop is part of the architecture
One of the most important things about The Factory is that it does not hide the review process behind a black box.
The spec stage produces review pages with previews, assumptions, references, and open questions. The build stage produces review pages with a deployed link, validation results, revision history, and structured feedback slots.
That means the human is still in the loop, but at the right abstraction level.
If the issue is conceptual, we fix the spec. If the issue is implementation detail, we refine the build. If the issue is missing input, we block the pipeline early instead of manufacturing confidence.
This keeps feedback precise, and it prevents us from treating all errors as code errors.
It also means the review process becomes part of the system’s memory. We are not just collecting approvals and rejections. We are collecting evidence about what kinds of specs succeed, what kinds of builds fail, and what changes actually improve the final onboarding.
What this gives us
The Factory gives us three things that matter more than raw automation:
- Throughput: A workflow that used to depend on repeated manual handoffs can now move continuously from design package to reviewable build.
- Reliability: The system is structured around concrete artifacts and validation gates, not just free-form agent output. Specs are checked. Builds are checked. Flow is checked. Review rounds are recorded.
- A better developer and designer experience: Instead of waiting for a vague status update, they get a spec to review, previews to inspect, a live onboarding to play, and a clear place to leave feedback.
We are not replacing judgment. We are moving judgment to the points where it creates the most leverage.
And because each run leaves behind structured outputs, we get something else too: a clearer picture of what actually works inside the factory.
What’s next
Today, The Factory already turns design inputs into playable Jest onboardings with far less manual stitching.
But the more important thing it produces is not just builds. It produces data about how onboardings are specified, built, reviewed, revised, and approved. Every spec, validation pass, feedback round, and shipped onboarding gives us a clearer picture of what actually works inside the factory.
Over time, that gives us something more valuable than automation: a system that can learn from its own output.
That learning can eventually flow upstream. First into better specs and build decisions. Then into designer assistance during ideation. Then into grounded A/B testing of new onboarding variants. And ultimately, into helping create stronger designer packages from the start, based not on guesswork, but on patterns drawn from real shipped onboardings and real review outcomes.
The long-term goal is not just a set of agents that execute tasks. It is a factory that gets better every time an onboarding moves through it.